Previous Sections
IntroductionThe problems
Current implementations
How Vinum addresses the Three Problems
The big picture
Some examples
Increased resilience: RAID-5
Object naming
Startup
Performance issues
This document shows the result of some initial performance measurements. Another set of results, on more modern disk hardware, can be found at http://www.shub-internet.org/brad/FreeBSD/vinum.html.Both sets of results show that the performance is very close to what could be expected from the underlying disk driver performing the same operations as Vinum performs: in other words, the overhead of Vinum itself is negligible. This does not mean that Vinum has perfect performance: the choice of requests has a strong impact on the overall subsystem performance, and there are some known areas which could be improved upon. In addition, the user can influence performance by the design of the volumes.
The following sections examine some factors which influence performance.
Note: Most of the performance measurements were done on some very old pre-SCSI-1 disk drives. The absolute performance is correspondingly poor. The intention of the following graphs is to show relative performance, not absolute performance.
The influence of stripe size
In striped and RAID-5 plexes, the stripe size has a significant influence on performance. In all plex structures except a single-subdisk plex (which by definition is concatenated), the possibility exists that a single transfer to or from a volume will be remapped into more than one physical I/O request. This is never desirable, since the average latency for multiple transfers is always larger than the average latency for single transfers to the same kind of disk hardware. Spindle synchronization does not help here, since there is no deterministic relationship between the positions of the data blocks on the different disks. Within the bounds of the current BSD I/O architecture (maximum transfer size 128 kB) and current disk hardware, this increase in latency can easily offset any speed increase in the transfer.In the case of a concatenated plex, this remapping occurs only when a request overlaps a subdisk boundary. In a striped or RAID-5 plex, however, the probability is an inverse function of the stripe size. For this reason, a stripe size of 256 kB appears to be optimum: it is small enough to create a relatively random mapping of file system hot spots to individual disks, and large enough to ensure than 95% of all transfers involve only a single data subdisk. The following graph shows the effect of stripe size on read and write performance, obtained with rawio. This measurement used eight concurrent processes to access volumes with striped plexes with different stripe sizes. The graph shows the disadvantage of small stripe sizes, which can cause a significant performance degradation even compared to a single disk.
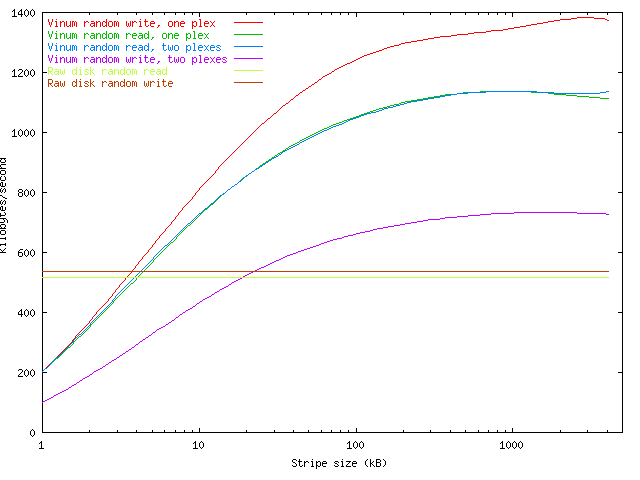
The influence of stripe size and mirroring
The influence of RAID-1 mirroring
Mirroring has different effects on read and write throughput. A write to a mirrored volume causes writes to each plex, so write performance is less than for a non-mirrored volume. A read from a mirrored volume, however, reads from only one plex, so read performance can improve.There are two different scenarios for these performance changes, depending on the layout of the subdisks comprising the volume. Two basic possiblities exist for a mirrored, striped plex.
One disk per subdisk
The optimum layout, both for reliability and for performance, is to have each subdisk on a separate disk. An example might be the following configuration, similar to the configuration shown above.
volume raid10
plex org striped 512k
sd length 102480k drive a
sd length 102480k drive b
sd length 102480k drive c
sd length 102480k drive d
plex org striped 512k
sd length 102480k drive e
sd length 102480k drive f
sd length 102480k drive g
sd length 102480k drive h
In this case, the volume is spread over a total of eight disks. This has the
following effects:
- Read access: by default, read accesses will alternate across the two plexes, giving a performance improvement close to 100%.
- Write access: writes must be performed to both disks, doubling the bandwidth requirement. Since the available bandwidth is also double, there should be little difference in througput.
Both plexes on the same disks
An alternative layout is to spread the subdisks of each plex over the same disks:
volume raid10
plex org striped 512k
sd length 102480k drive a
sd length 102480k drive b
sd length 102480k drive c
sd length 102480k drive d
plex org striped 512k
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive a
sd length 102480k drive b
This has the following effects:
- Read access: by default, read accesses will alternate across the two plexes. Since there is no increase in bandwidth, there will be little difference in performance through the second plex.
- Write access: writes must be performed to both disks, doubling the bandwidth requirement. In this case, the bandwidth has not increase, so write throughput will decrease by approximately 50%.
The influence of request size
As seen above, the throughput of a disk subsystem is the sum of the latency (the time taken to position the disk hardware over the correct part of the disk) and the time to transfer the data to or from the disk. Clearly the throughput is strongly dependent on the size of the transfer, as the following graph shows.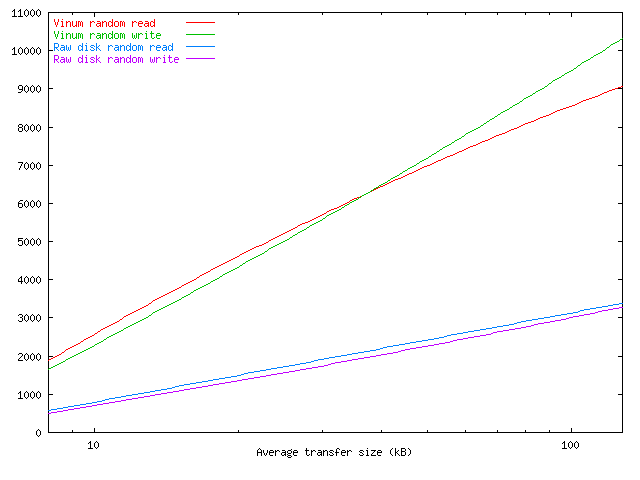
Throughput as function of transfer size
Unfortunately, there is little that can be done to influence the transfer size. In FreeBSD, it tends to be closer to 10 kB than to 30 kB.
The influence of concurrency
Vinum aims to give best performance for a large number of concurrent processes performing random access on a volume. The following graph shows the relationship between number of processes and throughput for a raw disk volume and a Vinum volume striped over four such disks with between one and 128 concurrent processes with an average transfer size of 16 kB. The actual transfers varied between 512 bytes and 32 kB, which roughly corresponds to UFS usage.
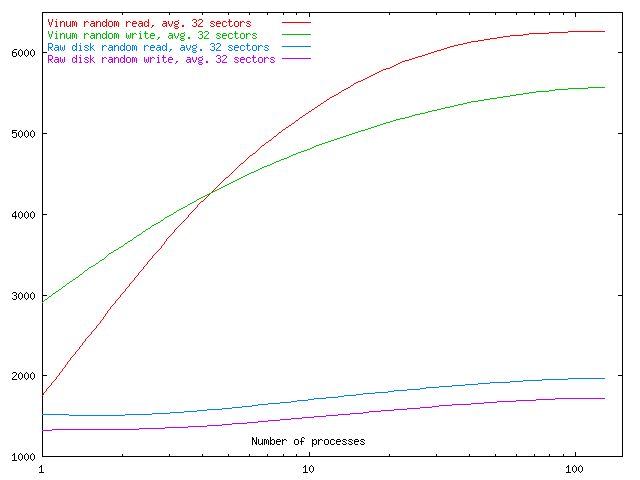
Concurrent random access with 32 sector transfers
This graph clearly shows the differing effects of multiple concurrent processes on the Vinum volume and the relative lack of effect on a single disk. The single disk is saturated even with one process, while Vinum shows a continual throughput improvement with up to 128 processes, by which time it has practically leveled off.
The influence of request structure
For concatenated and striped plexes, Vinum creates request structures which map directly to the user-level request buffers. The only additional overhead is the allocation of the request structure, and the possibility of improvement is correspondingly small.With RAID-5 plexes, the picture is very different. The strategic choices described above work well when the total request size is less than the stripe width. By contrast, consider the following transfer of 32.5 kB:
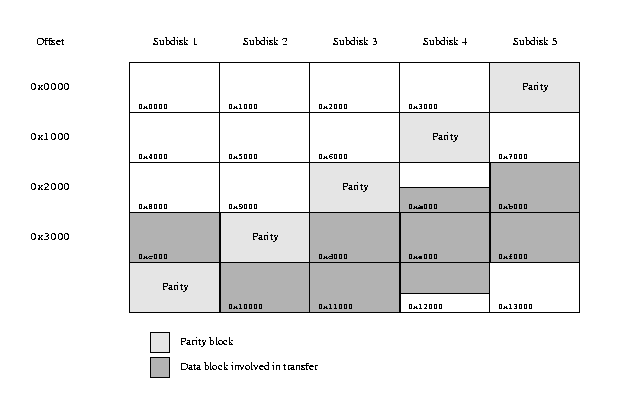
A sample RAID-5 transfer
In practice, this inefficiency should not cause any problems: as discussed above, the optimum stripe size is larger than the maximum transfer size, so this situation does not arise when an appropriate stripe size is chosen.

RAID-5 performance against stripe size
These considerations are shown in the following graph, which clearly shows the RAID-5 tradeoffs:
- The RAID-5 write throughput is approximately half of the RAID-1 throughput in the graph showing mirroring, and one-quarter of the write throughput of a striped plex.
- The read throughput is similar to that of striped volume of the same size.
Following Sections
The implementationDriver structure
Availability
Future directions
References