Previous Sections
IntroductionThe problems
Current implementations
How Vinum addresses the Three Problems
The big picture
Some examples
Increased resilience: RAID-5
Object naming
Startup
Performance issues
The implementation
At the time of writing, some aspects of the implementation are still subject to change. This section examines some of the more interesting tradeoffs in the implementation.Where the driver fits
To the operating system, Vinum looks like a block device, so it is normally be accessed as a block device. Instead of operating directly on the device, it creates new requests and passes them to the real device drivers. Conceptually it could pass them to other Vinum devices, though this usage makes no sense and would probably cause problems. The following figure, borrowed from ``The Design and Implementation of the 4.4BSD Operating System'', by McKusick et. al., shows the standard 4.4BSD I/O structure:This figure is © 1996 Addison-Wesley, and is reproduced with permission.
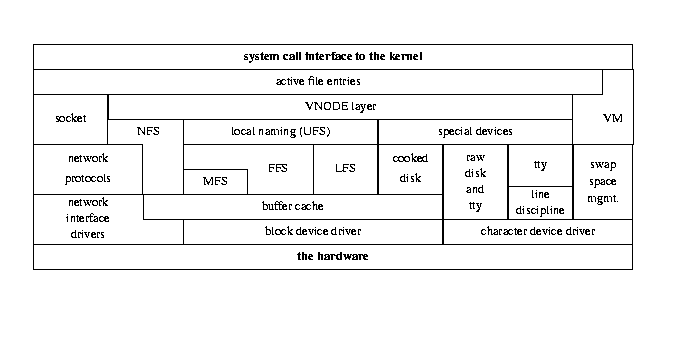
Kernel I/O structure, after McKusick et. al.
The following figure shows the I/O structure in FreeBSD after installing Vinum. Apart from the effect of Vinum, it shows the gradual lack of distinction between block and character devices that has occurred since the release of 4.4BSD: FreeBSD implements disk character devices in the corresponding block driver.
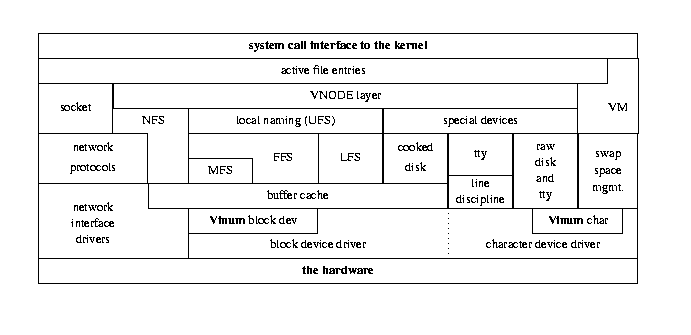
Kernel I/O structure with Vinum
Design limitations
Vinum was intended to have as few arbitrary limits as possible consistent with an efficient implementation. Nevertheless, a number of limits were imposed in the interests of efficiency, mainly in connection with the device minor number format. These limitations will no longer be relevant after the introduction of a device file system.| Restriction | Reasoning |
| Fixed maximum number of volumes per system. | In order to maintain compatibility with other versions of UNIX, it was considered desirable to keep the device numbers of volume in the traditional 8+8 format (8 bits major number, 8 bits minor number). This restricts the number of volumes to 256. In view of the fact that Vinum provides for larger volumes than disks, and current machines are seldom able to control more than 64 disk drives, this restriction seems unlikely to become severe for some years to come. |
| Fixed number of plexes per volume | Plexes supply redundancy according to RAID-1. For this purpose, two plexes are sufficient under normal circumstances. For rebuilding and archival purposes, additional plexes can be useful, but it is difficult to find a situation where more than four plexes are necessary or useful. On the other hand, additional plexes beyond four bring little advantage for reading and a significant disadvantage for writing. I believe that eight plexes are ample. |
| Fixed maximum number of subdisks per plex. | For similar reasons, the number of subdisks was limited to 256. It seldom makes sense to have more than about 10 subdisks per plex, so this restriction does not currently appear severe. There is no specific overall limitation on the number of subdisks. |
| Minimum device size | A device must contain at least 1 MB of storage. This assumption makes it possible to dispense with some boundary condition checks. Vinum requires 133 kB of disk space to store the header and configuration information, so this restriction does not appear serious. |
Memory allocation
In order to perform its functionality, Vinum allocates a large number of dynamic data structures. Currently these structures are allocated by calling kernel malloc. This is a potential problem, since malloc interacts with the virtual memory system and may trigger a page fault. The potential for a deadlock exists if the page fault requires a transfer to a Vinum volume. It is probable that Vinum will modify its allocation strategy by reserving a small number of buffers when it starts and using these if a malloc request fails.To cache or not to cache
Traditionally, UNIX block devices are accessed from the file system via caching routines such as bread and bwrite. It is also possible to access them directly, but this facility is seldom used. The use of caching enables significant improvements in performance.Vinum does not cache the data it passes to the lower-level drivers. It would also seem counterproductive to do so: the data is available in cache already, and the only effect of caching it a second time would be to use more memory, thus causing more frequent cache misses.
RAID-5 plexes pose a problem to this reasoning. A RAID-5 write normally first reads the parity block, so there might be some advantage in caching at least the parity blocks. This issue has been deferred for further study.
Access optimization
The algorithms for RAID-5 access are surprisingly complicated and require a significant amount of temporary data storage. To achieve reasonable performance, they must take error recovery strategies into account at a low level. A RAID 5 access can require one or more of the following actions:- Normal read. All participating subdisks are up, and the transfer can be made directly to the user buffer.
- Recovery read. One participating subdisk is down. To recover data, all the other subdisks, including the parity subdisk, must be read. The data is recovered by exclusive-oring all the other blocks.
-
Normal write. All the participating subdisks are up. This write proceeds in four
phases:
- Read the old contents of each block and the parity block.
- ``Remove'' the old contents from the parity block with exclusive or.
- ``Insert'' the new contents of the block in the parity block, again with exclusive or.
- Write the new contents of the data blocks and the parity block. The data block transfers can be made directly from the user buffer.
-
Degraded write where the data block is not available. This requires the following
steps:
- Read in all the other data blocks, excluding the parity block.
- Recreate the parity block from the other data blocks and the data to be written.
- Write the parity block.
- Parityless write, a write where the parity block is not available. This is in fact the simplest: just write the data blocks. This can proceed directly from the user buffer.
Combining access strategies
In practice, a transfer request may combine the actions above. In particular:- A read request may request reading both available data (normal read) and non-available data (recovery read). This can be a problem if the address ranges of the two reads do not coincide: the normal read must be extended to cover the address range of the recovery read, and must thus be performed out of malloced memory.
- Combination of degraded data block write and normal write. The address ranges of the reads may also need to be extended to cover all participating blocks.
Examples
The following examples illustrate these concepts:
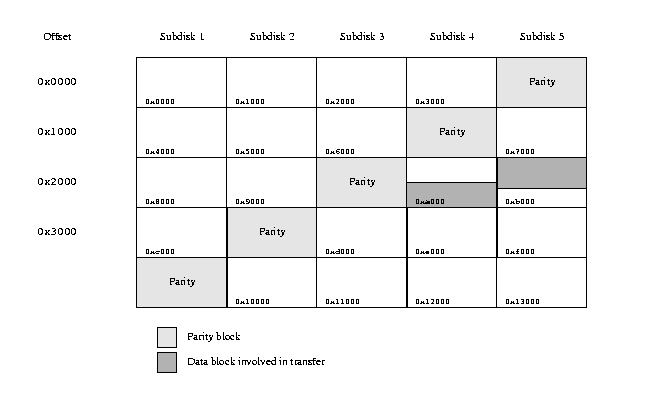
A sample RAID-5 transfer
Writing this area is significantly more complicated. From a programming standpoint, the simplest approach is to consider the transfers individually. This would create the following requests:
- Read the old contents of 4 sectors from subdisk 4, starting at offset 0x2800.
- Read the old contents of 4 sectors from subdisk 3 (the parity disk), starting at offset 0x2800.
- Perform an exclusive OR of the data read from subdisk 4 with the data read from subdisk 3, storing the result in subdisk 3's data buffer. This effectively ``removes'' the old data from the parity block.
- Perform an exclusive OR of the data to be written to subdisk 4 with the data read from subdisk 3, storing the result in subdisk 3's data buffer. This effectively ``adds'' the new data to the parity block.
- Write the new data to 4 sectors of subdisk 4, starting at offset 0x2800.
- Write 4 sectors of new parity data to subdisk 3 (the parity disk), starting at offset 0x2800.
- Read the old contents of 5 sectors from subdisk 5, starting at offset 0x2000.
- Read the old contents of 5 sectors from subdisk 3 (the parity disk), starting at offset 0x2000.
- Perform an exclusive OR of the data read from subdisk 5 with the data read from subdisk 3, storing the result in subdisk 3's data buffer. This effectively ``removes'' the old data from the parity block.
- Perform an exclusive OR of the data to be written to subdisk 5 with the data read from subdisk 3, storing the result in subdisk 3's data buffer. This effectively ``adds'' the new data to the parity block.
- Write the new data to 5 sectors of subdisk 5, starting at offset 0x2000.
- Write 5 sectors of new parity data to subdisk 3 (the parity disk), starting at offset 0x2000.
- Read the old contents of 4 sectors from subdisk 4, starting at offset 0x2800.
- Read the old contents of 5 sectors from subdisk 5, starting at offset 0x2000.
- Read the old contents of 8 sectors from subdisk 3 (the parity disk), starting at offset 0x2000. This represents the complete parity block for the stripe.
- Perform an exclusive OR of the data read from subdisk 4 with the data read from subdisk 3, starting at offset 0x800 into the buffer, and storing the result in the same place in subdisk 3's data buffer.
- Perform an exclusive OR of the data read from subdisk 5 with the data read from subdisk 3, starting at the beginning of the buffer, and storing the result in the same place in subdisk 3's data buffer offset.
- Perform an exclusive OR of the data to be written to subdisk 4 with the modified parity block, starting at offset 0x800 into the buffer, and storing the result in the same place in subdisk 3's data buffer.
- Perform an exclusive OR of the data to be written to subdisk 5 with the modified parity block, starting at the beginning of the buffer, and storing the result in the same place in subdisk 3's data buffer offset.
- Write the new data to 4 sectors of subdisk 4, starting at offset 0x2800.
- Write the new data to 5 sectors of subdisk 5, starting at offset 0x2000.
- Write the 8 sectors of new parity data to subdisk 3 (the parity disk), starting at offset 0x2000.
Degraded read
The following figure illustrates the situation where a data subdisk fails, in this case subdisk 4.
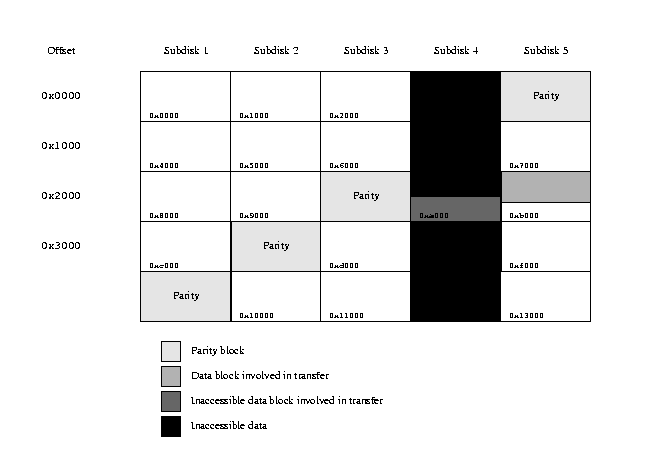
RAID-5 transfer with inaccessible data block
- Read 4 sectors each from subdisks 1, 2 and 3, starting at offset 0x2800 in each case.
- Read 8 sectors from subdisk 5, starting at offset 0x2800.
- Clear the user buffer area for the data corresponding to subdisk 4.
- Perform an ``exclusive or'' operation on this data buffer with data from subdisks 1, 2, 3, and the last four sectors of the data from subdisk 5.
- Transfer the first 5 sectors of data from the data buffer for subdisk 5 to the corresponding place in the user data buffer.
Degraded write
There are two different scenarios to be considered in a degraded write. Referring to the previous example, the operations required are a mixture of normal write (for subdisk 5) and degraded write (for subdisk 4). In detail, the operations are:- Read 4 sectors each from subdisks 1 and 2, starting at offset 0x2800, into temporary storage.
- Read 5 sectors from subdisk 3 (parity block), starting at offset 0x2000, into the beginning of an 8 sector temporary storage buffer.
- Clear the last 3 sectors of the parity block.
- Read 8 sectors from subdisk 5, starting at offset 0x2000, into temporary storage.
- ``Remove'' the first 5 sectors of subdisk 5 data from the parity block with exclusive or.
- Rebuild the last 3 sectors of the parity block by exclusive or of the corresponding data from subdisks 1, 2, 5 and the data to be written for subdisk 4.
- Write the parity block back to subdisk 3 (8 sectors).
- Write 5 sectors user data to subdisk 5.
Parityless write
Another situation arises when the subdisk containing the parity block fails, as shown in the following figure.
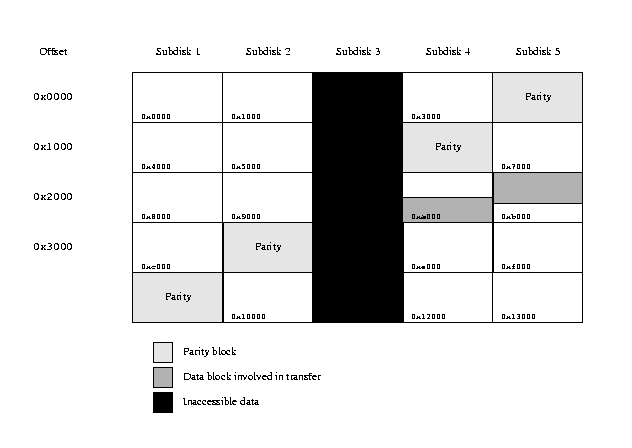
RAID-5 transfer with inaccessible parity block
Following Sections
Driver structureAvailability
Future directions
References